
Whether you think AI is on the cusp of replacing millions of jobs, or an overblown Google search designed to agree with you, one thing is sure: people whose job it is to analyze complex medical data might want to pay attention...
For years, biomedical research has had a problem: too much data, not enough people who know how to wrangle it - or simply that it took months to do so. Modern health studies generate oceans of molecular information - gene expression, DNA methylation, microbiome profiles. Turning that into useful predictions about disease risk or pregnancy outcomes typically requires teams of data scientists, months of coding, and endless debugging.
Now, according to a new study in Cell Reports Medicine, some AI systems can do much of that work in minutes - and in at least one case, they did it better than humans.
The Test: AI vs. the Crowd
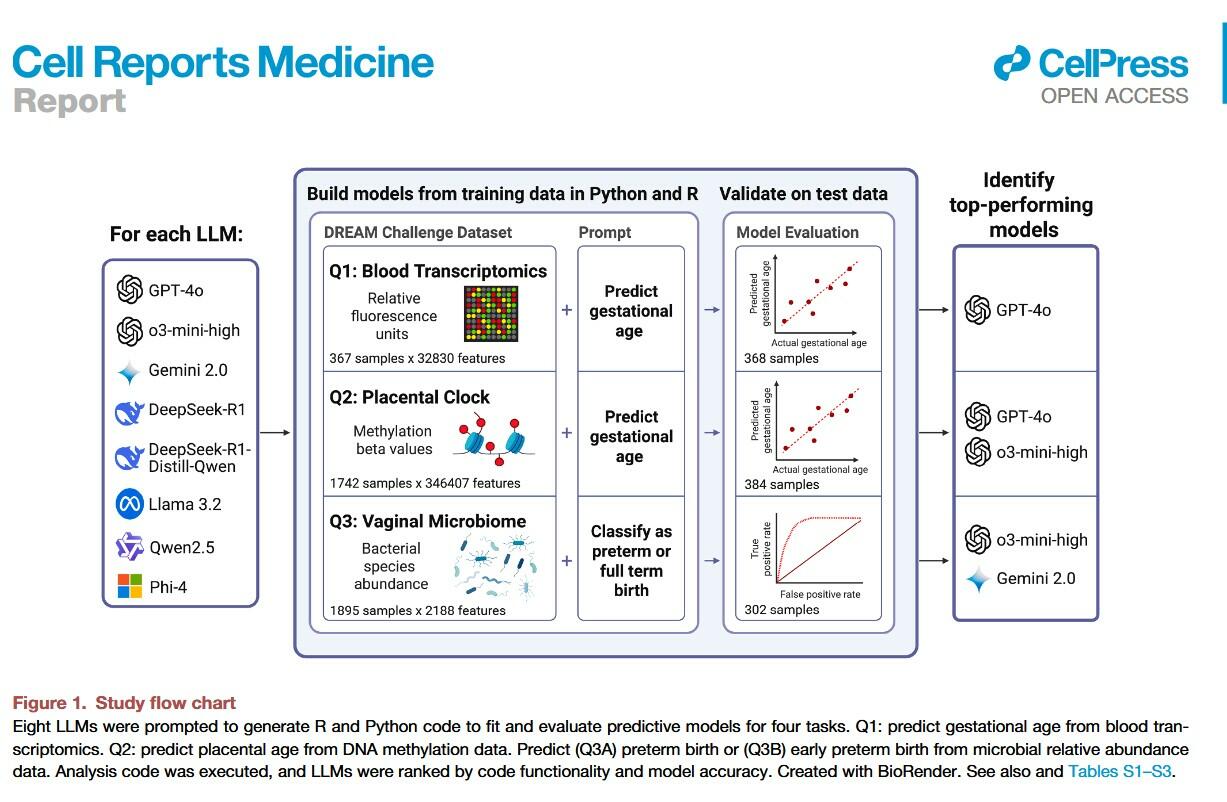
Researchers at UC San Francisco and Wayne State University took eight large language models - the same class of AI that powers systems like ChatGPT - and dropped them into a serious biomedical competition. The team used data from three previous international DREAM Challenges, where more than 100 research teams had built predictive models tackling reproductive health questions such as:
-
Can you predict gestational age from blood gene expression?
-
Can you estimate the biological age of the placenta from DNA methylation?
-
Can you detect risk of preterm birth from vaginal microbiome data?
So this is modern AI creating modeling code in Python vs. human-coded predictive models, not humans manually processing the data (to be clear).
One dataset included around 360,000 molecular features. Another required parsing genomic data from public repositories. In the original competitions, human teams spent up to three months developing and tuning their models.
The AI systems were given a carefully written prompt describing the dataset and the task. Then they had to generate executable R or Python code from scratch. Researchers ran that code and measured how well the resulting models performed on unseen test data.
No special hints. No iterative coaching. Just one shot.
The Results: Faster, Sometimes Better
Four of the eight AI systems successfully generated working code and usable prediction models.
One of them - OpenAI’s o3-mini-high - completed nearly all the tasks and scored the highest overall.
But here’s the part that surprised even the researchers: on the placental aging task, one AI-generated model outperformed the top human team from the original challenge. The difference was statistically significant.
In other words, the AI built a more accurate predictor of placental gestational age than the best human competitors had.
And it generated the code in seconds to minutes.
By contrast, the human teams had months to refine their approaches. Some built complex multi-stage random forest systems and leveraged additional clinical information. The AI, using a relatively straightforward ridge regression model, still won.
Across the other tasks, AI models generally matched the median performance of human participants - solidly competitive, though not always beating the top experts.
Why This Matters
Preterm birth affects roughly 11 percent of infants worldwide and remains a leading cause of neonatal mortality. Clinicians still lack reliable predictive tools for many pregnancy complications.
Better models could mean; earlier identification of at-risk pregnancies, more precise timing of interventions, and reduced long-term complications for children - among other things. But building those models is slow. - requiring extensive writing, debugging, and standardizing analysis pipelines.
And this is where the LLMs kick ass - given that they're especially strong at generating structured, reproducible workflows: loading data, splitting training and test sets properly, fitting models, calculating performance metrics, and even producing plots. Notably, none of the successful AI systems accidentally “leaked” test data into training - a surprisingly common human mistake that can inflate results.
That said, AI is still in its infancy and it wasn't all a slam dunk. In fact, half of the tested models failed outright - often due to basic coding issues like referencing nonexistent packages or mishandling data formats. R code proved more reliable than Python in this setting.
Even the top models were stochastic: run the same prompt multiple times, and you might get slightly different modeling strategies or results.
And there’s a deeper concern. If many researchers rely on similar AI systems, they may converge on similar modeling approaches. That standardization could improve reproducibility - but it might also reduce methodological creativity.
Where is this Going?
Large language models are already showing promise in reading medical records, generating radiology reports, and assisting in pathology analysis. What’s new here is that they’re moving beyond language tasks into hands-on data science, writing actual code.
The authors emphasize that human oversight remains critical. AI models can hallucinate, misunderstand instructions, or silently make errors. Advanced API-based systems also come with cost and privacy considerations, particularly in clinical contexts.
The question is; will AI in 1, 3, 5 years from now be error free? No hallucinations and generally considered reliable?
h/t Capital.news















































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































{kind=link}
{kind=link}
{kind=link}